How to get started in Machine Learning and Data Science from scratch?
In this post, we will see how you can get started in machine learning and data science from scratch.
Courses to take
Andrew Ng’s Stanford course & Coursera course are probably the best-in-class courses to get started. If you have some good background & interest in Maths then you can also take some of his math heavy courses like this one. There are tons of courses on the platforms like Udemy & Udacity. Almost every famous course is good to start with.
One good way to get started is to learn in a BFS(breadth first search) manner instead of DFS(depth first search). Meaning, learn every topic/concept/algorithm once & try to use it on some project or dataset in languages like Python. Instead of learning everything at once & then trying to implement everything, BFS approach is better IMHO.
So, what you can do is, once you learn a topic like linear regression, you can try to implement/use it in Python on some project.
Benefit of directly implementing what we have learned is, we get the overall idea of how it looks in the code. Implementing something in code has a different set of challenges than just understanding the theory part.
You can pick a dataset from Kaggle datasets and try to use an algorithm or a concept you have just learned on that dataset and see how it’s working.
Once you’ve learned a couple of algorithms/concepts, you can try all of them together on a dataset to see which algorithm performs better. Every algorithm has some strong points & some weak points. We need to decide whether a particular algorithm will work on a dataset or not.
So, here are the steps you can follow:
- Take the above free courses to learn basic concepts.
- Learn one concept at a time.
- Once a concept is learned theoretically, try to implement it in Python on some dataset.
- Repeat step 2 again and again till the course finishes.
- Implement all the concepts together on a dataset, and see which works better. This will help in making your intuitions better about ML models.
And a side benefit is, you can also add above work in your portfolio as projects.
Machine learning project cycle
A typical ML project involves below steps.
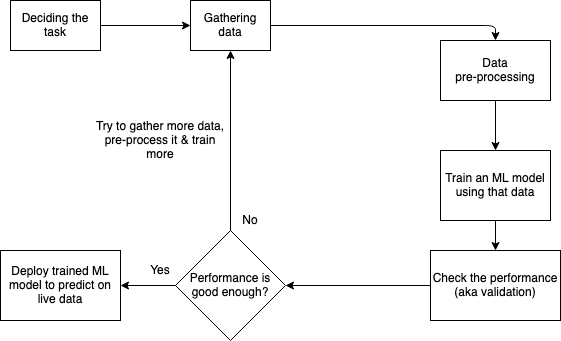
- First, we decide the task/project we need to work on.
- This step seems naive but it’s important. Not all problems are a good fit for machine learning.
- Then we start gathering publicly available training data for that task.
- Once we get the data, we pre-process that data & then do EDA(Exploratory Data Analysis) on it.
- Cleaning: Remove extra data we don’t want. Like outliers.
- Filling/removing null values.
- EDA: Explore the data & try to find some insights. Like by plotting graphs.
- Feature engineering: creating meaningful data out of data we already have.
- Choose ML model(s) & train them with the processed data.
- Check the performance on the validation(aka held-out) dataset.
- For cross-validation, we can use methods like k-fold, stratified k-fold to see the model is robustly training.
- Purpose of this step is to check if the model is overfitting.
- As a last step,
- If performance is good enough, we can deploy that ML model on production on the future unseen data(i.e. test data).
- If the performance is not good enough, we can go back to step #2 to collect some more data if can and continue the cycle.
So, above is the journey from start to end. We started with raw data and after following all the steps, we finally deployed that model on the server which will make predictions 24x7.
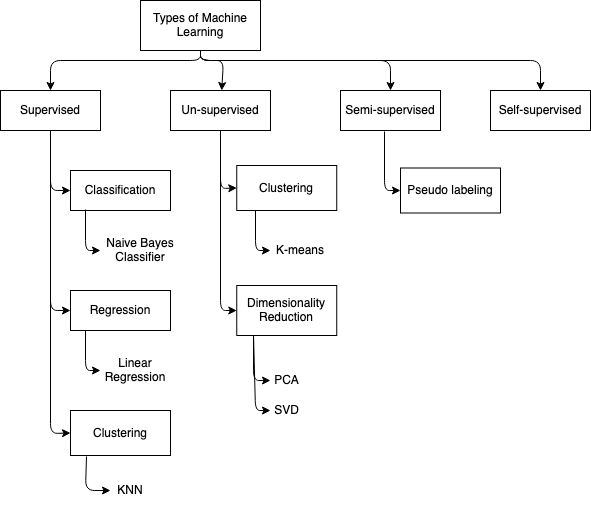
Here are the types and sub-types of machine learning. Which may help you in choosing the models.
Role of Kaggle competitions
Kaggle competitions is, according to me, the best way to learn ML or data science to keep ourselves updated with the latest research. People from all over the world try to solve the same problem & share their learning with each other.
Benefit we get is, we get to see how other people are trying to solve the problem. Sometimes, people try innovative approaches to solve problems which we would have never thought of. That’s the benefit of a community.
First we try to solve the problem by ourselves, and then see how others are doing it. We notice things like,
- Which models have people chosen to solve the problem?
- What type of pre-processing techniques are working the best?
- How different types of models are performing on the validation data?
At first, the goal of participating in these competitions should not be to earn ranks in the top 1% or top 5%, but to learn as much as we can. Because when brilliant people from all over the world are participating, getting ranks in the top 1% becomes not that easy a task. Anyway, we came here to learn in the first place.
So, don’t get discouraged if your ranks are lower in the competitions. Learning and exploring the field is the only goal here. But just see, how do the top 1% people are solving the problem?
Importance of deploying ML models on cloud
Tasks like gathering data, pre-processing the data, training ML models, plotting different graphs are important, but not the only things that matter in the full picture.
Deployment of those trained ML models on the web is another task altogether. Because when we try to deploy the model via an API, we may see some different problems like high latency, breakdown of the server etc.
Benefit of deploying the ML model on the web is, instead of seeing your code on GitHub, people can directly see your model making good predictions on their laptop/phone.
How to deploy a trained ML model?
Let’s take an example. You trained a model which can predict which number out of 0-9 is written in a given image. Now, it will be a better choice if you deploy that trained model on some website where people can upload a photo & your model will make predictions on it.
Investing more time in fancy CSS or JavaScript is not required, just a simple upload button & model will predict what number is written in the image.
Doing all these will also make you learn cloud services like Azure, Google cloud or AWS. Which is obviously a good skill to learn. Google cloud provides one-time $300 free credit to your account using which you can buy a low-end CPU machine with basic configurations like 2 CPU cores & 2 GB RAM, and deploy your model using Flask, Fast API or django.
Doing this will also make your project stand out in an interviewer’s eye and build your reputation. Because not every person takes an effort and does all these. And anyway, you get to learn a whole bunch of other things that are not related to ML, but are important like,
- How to use cloud services like Azure, Google cloud or AWS?
- How to deploy an ML model via an API using Flask, Fast API or django?
- How to make the model scalable with low latency and 100% uptime without crashing the server.
And once you do all these tasks, you will realize things like, deploying and maintaining large deep learning models are comparatively harder than simple ML models like logistic regression and decision tree. High-end compute is required to make these models work like GPU or TPU.
You can buy a public URL & host all of your projects there. Using which anyone can access & see your work. There are tons of platforms like Heroku, Netlify and python anywhere where you can host your code/project for free. Follow blogs like this, to learn how you can do it.
Once you repeat the above things 2-3 times, you will have solid projects to show in your portfolio or in the resume. And now you have significant knowledge about ML too!
So, we started with raw data, we pre-processed it, we trained ML models, we cross-validated it & finally, we deployed it!
I have written a similar type of blog here explaining how to grow & maintain your knowledge about ML. So, this is how you can get started in machine learning! Have a happy life, cheers!